Open Hype
Keyboard-driven alt frontend for Hyperliquid with risk-first orders, ICT killzones, and a paper options trader.
I built Open Hype because the official Hyperliquid interface is too simple for the way I actually trade. It's fine if you're clicking buy and sell, but the moment you want to do real chart work — fib retracements, mapping out structure, watching how price reacts inside the London or NY killzone — you're eyeballing and tabbing between tools. I wanted one screen.
The first thing I added was automatic ICT killzone visualization. Asia, London, NY — they highlight on the chart on their own, DST-aware, so I'm not redrawing sessions every day. Then fib retracements. Hyperliquid not having them out of the box is one of those small frictions you don't notice until it's gone.
The order panel is risk-first. On the official UI, if I want a setup with a defined dollar risk, I'm reversing out the position size by hand — stop distance, leverage, fees. Open Hype flips that. I type a risk amount, shift+click to draw the long or short box on the chart, and size, leverage, TP, and SL fall out of the geometry. Reward is whatever ratio the box gives. It changed how I trade — fewer impulsive entries, because the stop has to exist before the order does.
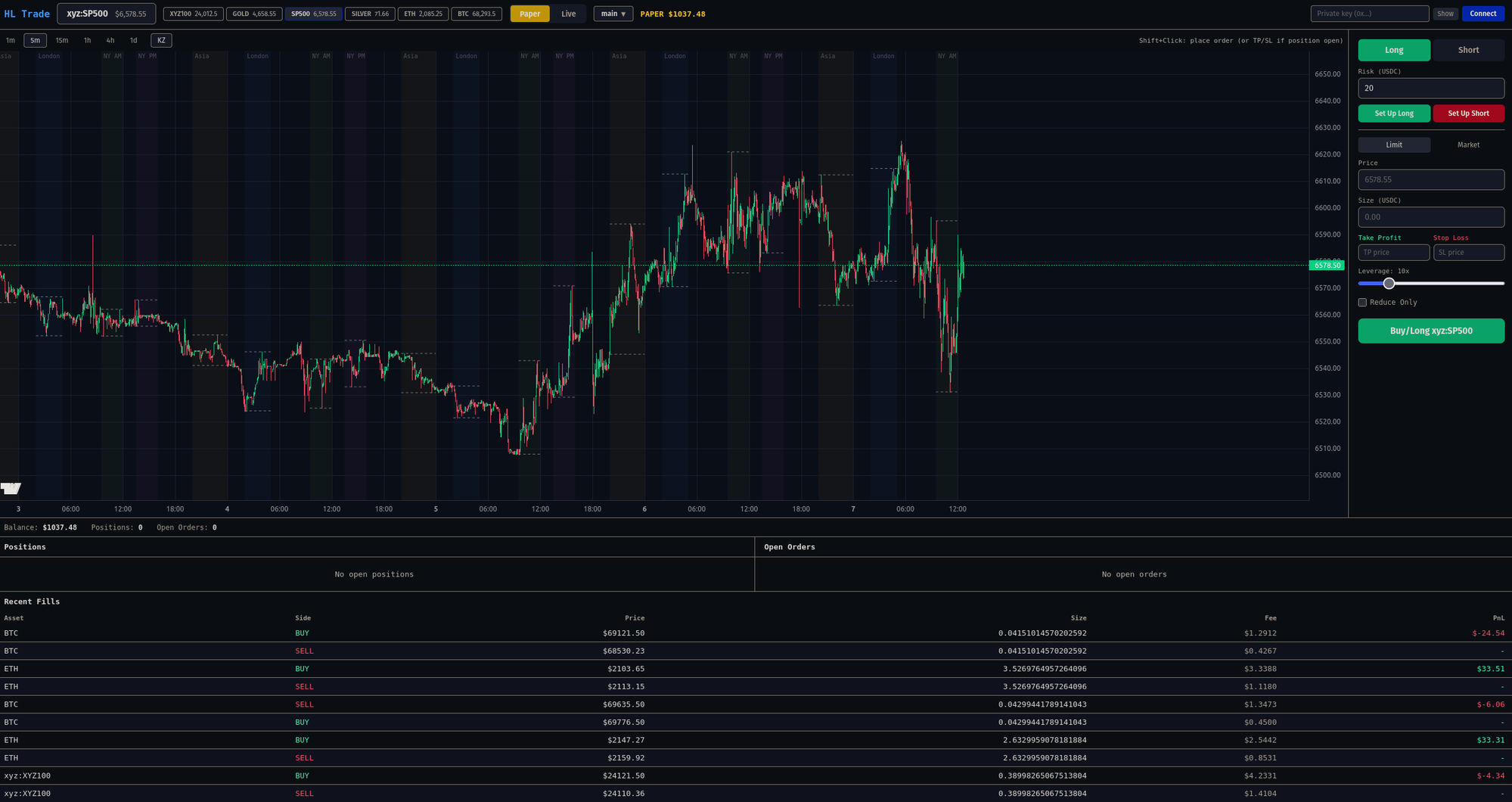
Paper trading was the original reason I started. Other DEXes offer real-time data, but none with the asset coverage or liquidity of Hyperliquid, and I wanted somewhere to test setups without putting money on the line. The paper engine simulates HL's fee schedule accurately enough that PnL matches live results, which matters more than people realize — most paper traders feel free in a way real trading doesn't, and you end up learning the wrong lessons.
Later I added an options paper trader, which I haven't seen anywhere else. It pulls chain data from Yahoo Finance since HL doesn't do options, and it's built specifically for practicing swing trades — holding through expiry, scaling in over days, watching theta eat a position you held too long. Pricing, margin, and PnL live in their own engine module with tests, because options PnL is unforgiving and a sign error doesn't announce itself for a week. The trades I take on it are the trades I'd take with real money — same size, same conviction — which is the only way paper trading produces useful feedback.
I've been using it daily for months. It's stable. I haven't deployed it publicly — nobody should trust an unofficial frontend with their keys, and I don't want to be in the support business for other people's losses — but the source is up and it's a few commands to run locally.

